
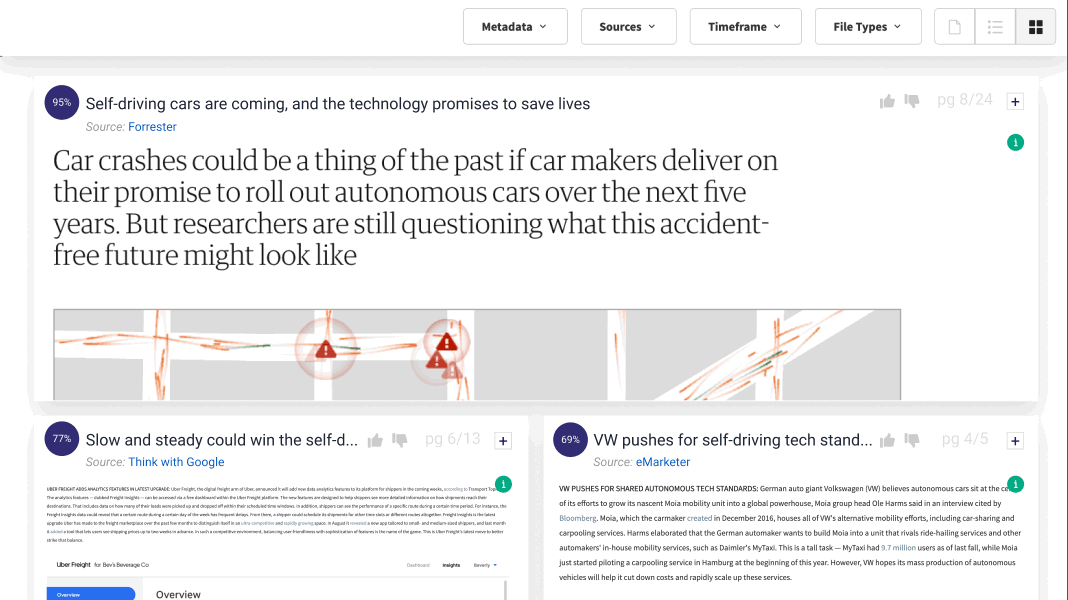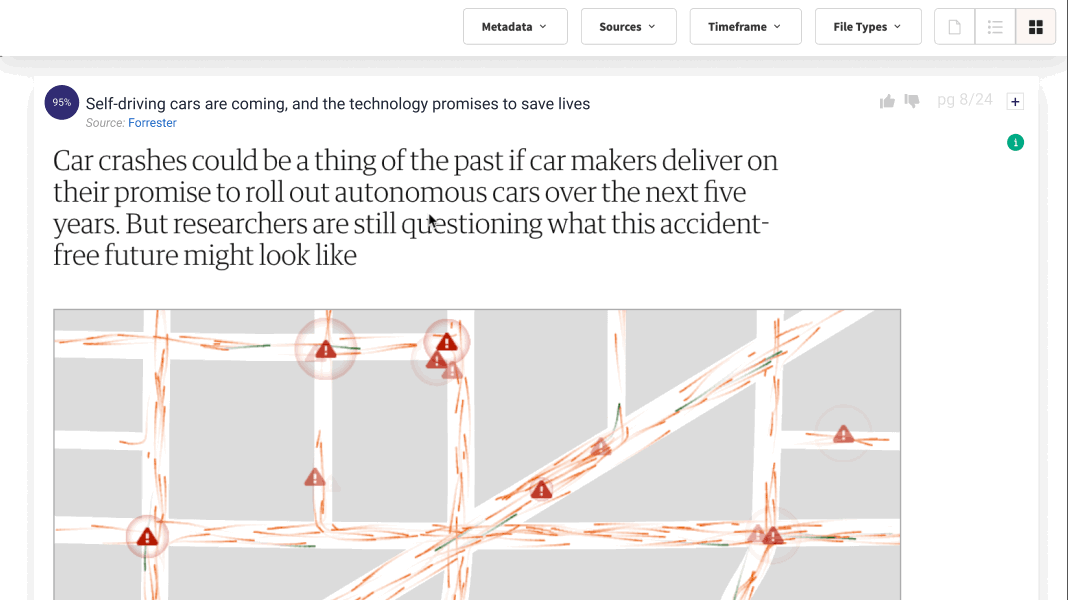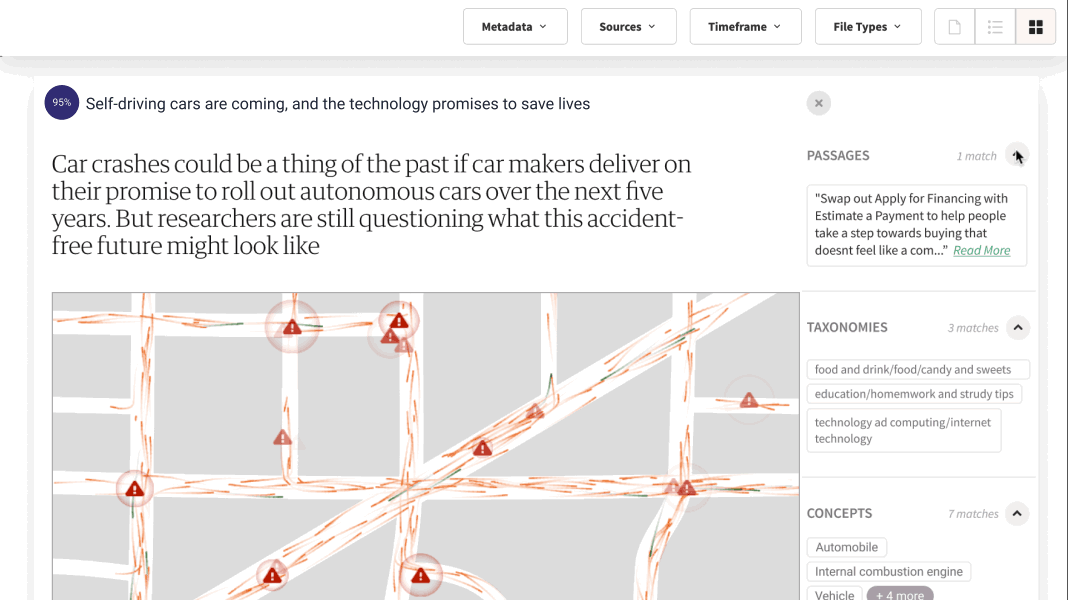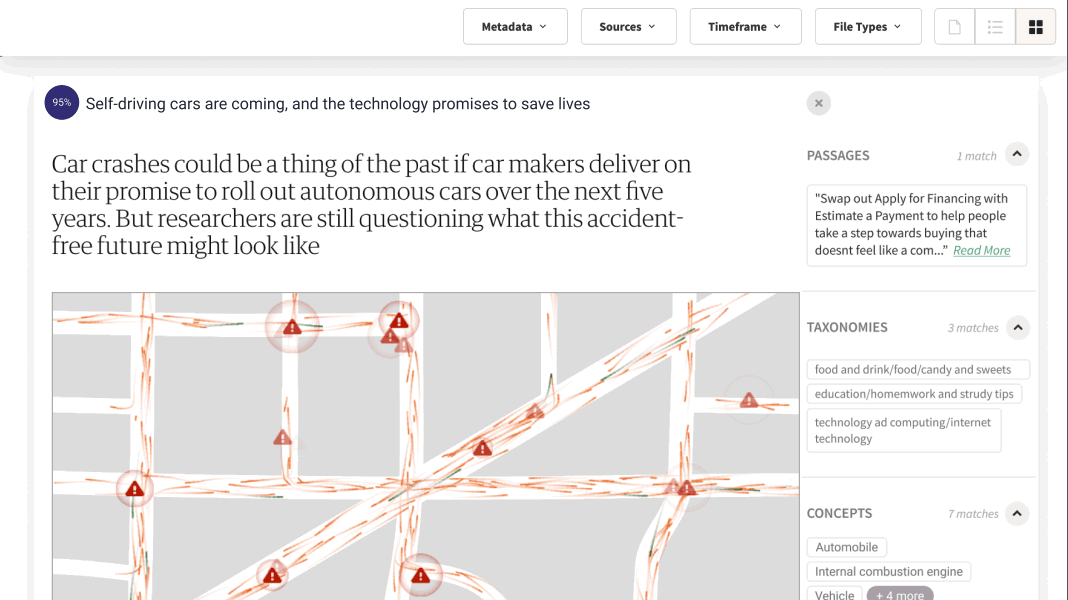
The phrase “garbage in, garbage out” has been a part of computing vernacular from the beginning. For this new generation of AI tools, they will only be as smart as the data you provide them. Provide a bounty of high-quality and relevant data, and your AI can achieve its potential. However where there are gaps in access to data, expectations for the AI’s performance should be very low.
As the creators of Lucy, an AI used to support knowledge management in the enterprise, we have spent countless hours testing, training, and tuning AI over the last seven years. We’ve reviewed vast quantities of customer data and found—beyond question—that the leading reason why AI does not respond with the desired answer is a lack of access to the right foundational information.
As AI systems evolve, one critical but infrequently discussed dependency is ensuring access to the right data. As companies invest more in applying AI to company knowledge, this will become increasingly crucial.
If you’ve had a chance to work with AI in your business, do you know what information the AI has access to? Do you know the depth of information available to the AI? Or is it a black box of unknown origin? Corporate users should expect that AIs have great access to the information needed within their security parameters and access rights. If not, what good is the AI to you?
So how do we ensure the AI has access to the right information?
Data Access
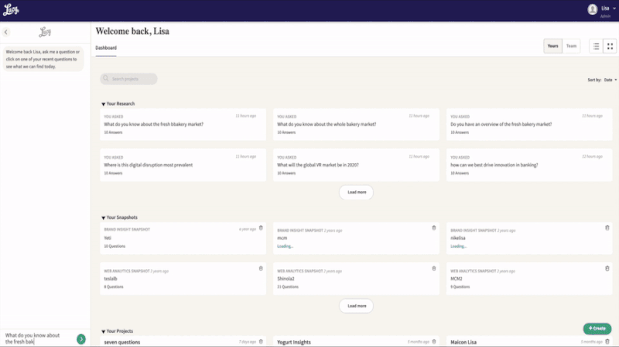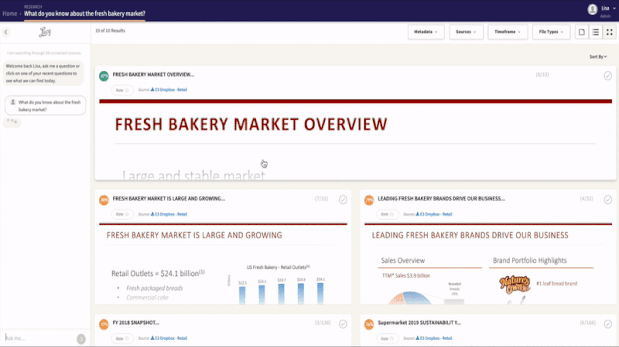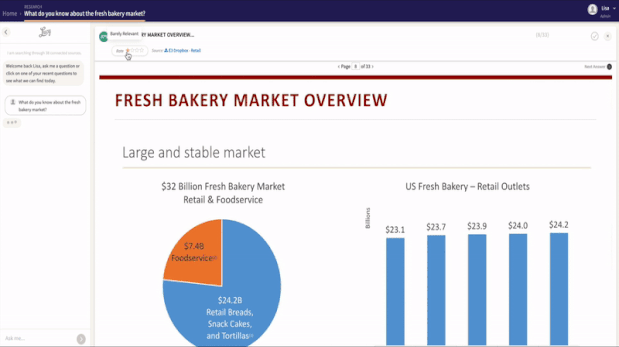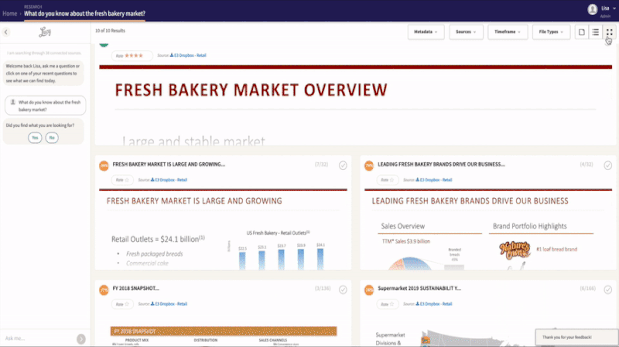
Start with mapping out the data sources the AI should access to support the users it will assist. Think of adding someone new to the team (e.g., a marketer, salesperson, analyst, or PM). What data sources would you ask IT to enable for them? Treat the AI as another team member, following the same path for connectivity and security (SSO, data security, access rights).
Getting Data into the System
Once you know the problem you are trying to solve, you can start to create a Content Policy and have some idea of what should go in to your solution. This Content Policy needs to be able to scale to the needs of your business and also to the effort and capability of your team. The next step is loading data in to meet those needs.
Manual Curation: At one extreme is the method of manual curation, where files are hand-picked for the AI. This ensures the highest data quality, however, this approach has significant drawbacks. Fundamentally, your super-powerful AI is limited by what content your humans have manually selected. This approach puts the onus on the user to add content that she deems valuable. New data is constantly being created, and building workflows to manage it can consume excessive time and resources. Additionally, organizations relying on manual curation often have far less data in their systems compared to those using automated methods. The immense effort required for manual curation can lead to substantial knowledge gaps, making it nearly impossible to curate all valuable information effectively. However, this approach has significant drawbacks. Most organizations have too much data and too little time to manage this task manually. New data is constantly being created, and building workflows to manage it can consume excessive time and resources. Additionally, organizations relying on manual curation often have far less data in their systems compared to those using automated methods. The immense effort required for manual curation can lead to substantial knowledge gaps, making it nearly impossible to curate all valuable information effectively.
Automated Indexing: On the other end of the spectrum is automated indexing. Tools that perform automated indexing can connect to and index vast amounts of data with minimal human involvement. This capability allows AI to access far more data than could ever be manually curated. These systems can read, listen, watch, learn, and tag data in hours or days—tasks that would take an army of people years to accomplish. However, a potential downside is that many customers have data that can be messy, outdated, or contain quality and relevance issues. This can affect the overall performance of the AI.
Automated Curation: Automated curation combines the strengths of both manual curation and automated indexing. By taking Automated indexing and applying Rules and Workflows on top to form a Content Policy, your AI stays up to date and can be informed in its generative actions while scaling beyond what’s humanly possible. This approach reduces noise and filters out inappropriate data, enabling the AI to focus on the most important content. From our perspective, automated curation leads to the best results with minimal human intervention and supports any level of scaling required. At Lucy, we believe in the technology’s ability to empower human input and extend it beyond what would be possible manually. We have invested considerable time and energy into advancing and evolving our capabilities to support this type of automated curation.
In the end, your AI efforts will only support you and succeed to the extent that you have the right data available. A key strategic focus for every organization should be managing how to get the right data into their AI tools.





